LeetCode 820. Short Encoding of Words
每日題。一眼就覺得又是字典樹,但是這題目描述看了好久才看懂,說什麼indices的很難理解。
題目
words陣列的有效編碼由字串s和索引陣列indices所組成:
- words.length == indices.length
- 以’#’符號來分隔所有單字
- 每個indices[i],代表從indices[i]開始直到下一個’#’為止的子字串等於word[i]
輸入陣列words,求有效編碼字串s的最短長度。
解法
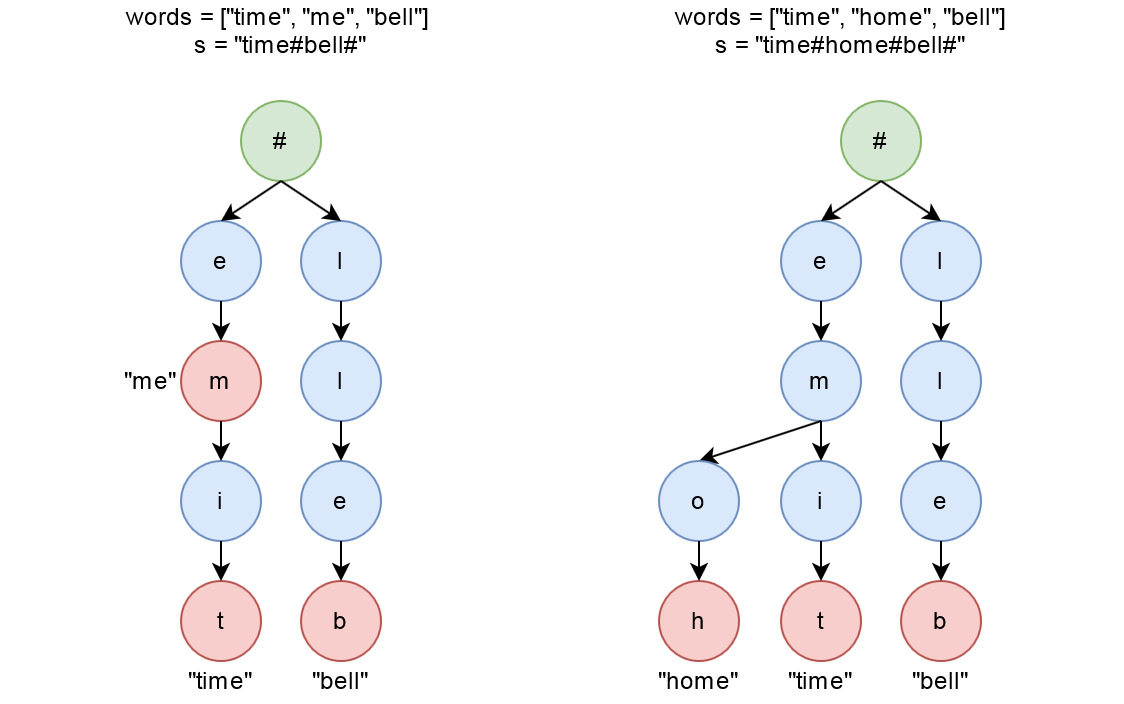
看範例看好久才搞懂,簡單來說就是要把相同後綴的單字壓縮在一起,例:
words = [“time”, “me”, “bell”]
加入符號 = [“time#”, “me#”, “bell#”]
壓縮重疊的部分 = [“time#”,”bell#”]
s = “time#bell#”
一般的字典樹是保存共通前綴,但我們這次要共通後綴,所以把每個單字反轉後再建樹。
維護空節點dummy作為樹根,遍歷words中每個單字w,以倒序建立字典樹。
再寫一個輔助函數dfs來遍歷建好的字典樹,找到所有葉節點,代表已經是單字的第一個字元了,以其長度加上”#”符號的1到答案中。
class Node:
def __init__(self):
self.child=defaultdict(Node)
class Solution:
def minimumLengthEncoding(self, words: List[str]) -> int:
dummy=Node()
for w in words:
curr=dummy
for c in w[::-1]:
curr=curr.child[c]
ans=0
def dfs(node,size):
nonlocal ans
if not node.child:
ans+=size
return
for v in node.child.values():
dfs(v,size+1)
dfs(dummy,1)
return ans
大神不用字典樹的解法。
假設words包含”bell”,那麼”ell”、”ll”還有”l”都被包含了。
建立一個集合s,先裝進words中所有的單字,在遍歷words中每個單字w,排除掉w所產生的所有後綴。
最後s只會剩下所有合法的單字,將其加上’#’後計算長度總和。
class Solution:
def minimumLengthEncoding(self, words: List[str]) -> int:
s=set(words)
for w in words:
for i in range(1,len(w)):
pref=w[i:]
if pref in s:
s.remove(pref)
return sum(len(w)+1 for w in s)